Java Database Connectivity
Java Database Connectivity (en español: Conectividad a bases de datos de Java), más conocida por sus siglas JDBC,12 es una API que permite la ejecución de operaciones sobre bases de datos desde el lenguaje de programación Java, independientemente del sistema operativo donde se ejecute o de la base de datos a la cual se accede, utilizando el dialecto SQL del modelo de base de datos que se utilice.
El API JDBC se presenta como una colección de interfaces Java y métodos de gestión de manejadores de conexión hacia cada modelo específico de base de datos. Un manejador de conexiones hacia un modelo de base de datos en particular es un conjunto de clases que implementan las interfaces Java y que utilizan los métodos de registro para declarar los tipos de localizadores a base de datos (URL) que pueden manejar. Para utilizar una base de datos particular, el usuario ejecuta su programa junto con la biblioteca de conexión apropiada al modelo de su base de datos, y accede a ella estableciendo una conexión; para ello provee el localizador a la base de datos y los parámetros de conexión específicos. A partir de allí puede realizar cualquier tipo de tarea con la base de datos a la que tenga permiso: consulta, actualización, creación, modificación y borrado de tablas, ejecución de procedimientos almacenados en la base de datos, etc.
Drivers JDBC
Los drivers JDBC drivers son adaptadores del lado del cliente (instalados en la máquina cliente, no en el servidor) que convierten la petición proveniente del programa JAVA a un protocolo que el SGBD pueda entender.
- Driver JDBC Tipo 1 (también llamado Puente JDBC-ODBC) convierte el método JDBC a una llamada a una función ODBC. Utiliza los drivers ODBC para conectar con la base de datos.
- Driver JDBC Tipo 2 (también llamado driver API-Nativo) convierte el método JDBC a llamadas nativas de la API de la base de datos. Es más rápido que el puente JDBC-ODBC pero se necesita instalar la librería cliente de la base de datos en la máquina cliente y el driver es dependiente de la plataforma.
- Driver JDBC Tipo 3. Hace uso de un Middleware entre el JDBC y el SGBD.
- Driver JDBC Tipo 4 (también llamado Driver Java Puro directo a la base de datos). Es independiente a la plataforma.

Introducción
En este trabajo damos un breve resumen de la biográfica de Edgar Frank Codd, decimos quien es y nos centramos en las 12 reglas que propuso para Diseño de Bases de Datos Relacionales y como están implementadas en las diferentes gestores de Bases de datos.
Edgar Frank Codd
Nacido en Inglaterra el 23 de agosto de 192, Edgar es considera el padre de las bases de datos relacional.
En 1969 Edgar Codd inventó el modelo relacional, el modelo de bases de datos más usado hoy en día y para muchas personas, el único que conocen. Desde el sistema R de IBM a Oracle han pasado 30 años y aún es el modelo dominante. Inicialmente el apoyo de IBM a los sistemas de bases de datos tradicionales (de redes) era mayoritario, poderoso y agresivo. Sólo años más tarde, en 1978, durante una reunión técnica de alto nivel el modelo relacional llamó la atención del presidente de IBM, Frank Cary. Más tarde IBM anunció SQL/DS, su primer producto relacional comercial en 1981, seguido de DB2 en 1983. Sin embargo esta tardanza en adoptar el modelo relacional significó perder un mercado que tomaron otros. El trabajo inicial de Codd fue publicado en Communications of the ACM en 1970. Su trabajo sobre normalización de bases de datos fue publicado como un informe técnico de IBM en 1971. Ocho años más tarde, en ACM Transactions of Database Systems, publicó varias extensiones al modelo relacional. En 1985 postuló una lista de 13 reglas que debía cumplir un producto de bases de datos para ser llamado relacional.
12 reglas de Codd
Codd se percató de que existían bases de datos en el mercado las cuales decían ser relacionales, pero lo único que hacían era guardar la información en las tablas, sin estar estas tablas literalmente normalizadas; entonces éste publicó 12 reglas que un verdadero sistema relacional debería tener aunque en la práctica algunas de ellas son difíciles de realizar. Un sistema podrá considerarse “más relacional” cuanto más siga estas reglas.
– Regla 0: el sistema debe ser relacional, base de datos y administrador de sistema. Ese sistema debe utilizar sus facilidades relacionales (exclusivamente) para manejar la base de datos.
– Regla 1: la regla de la información, toda la información en la base de datos es representada unidireccionalmente, por valores en posiciones de las columnas dentro de filas de tablas. Toda la información en una base de datos relacional se representa explícitamente en el nivel lógico exactamente de una manera: con valores en tablas.
– Regla 2: la regla del acceso garantizado, todos los datos deben ser accesibles sin ambigüedad. Esta regla es esencialmente una nueva exposición del requisito fundamental para las llaves primarias. Dice que cada valor escalar individual en la base de datos debe ser lógicamente direccionable especificando el nombre de la tabla, la columna que lo contiene y la llave primaria.
– Regla 3: tratamiento sistemático de valores nulos, el sistema de gestión de base de datos debe permitir que haya campos nulos. Debe tener una representación de la “información que falta y de la información inaplicable” que es sistemática, distinto de todos los valores regulares.
– Regla 4: catálogo dinámico en línea basado en el modelo relacional, el sistema debe soportar un catálogo en línea, el catálogo relacional debe ser accesible a los usuarios autorizados. Es decir, los usuarios deben poder tener acceso a la estructura de la base de datos (catálogo).
– Regla 5: la regla comprensiva del sublenguaje de los datos, el sistema debe soportar por lo menos un lenguaje relacional que:
- Tenga una sintaxis lineal.
- Puede ser utilizado de manera interactiva.
- Soporte operaciones de definición de datos, operaciones de manipulación de datos (actualización así como la recuperación), seguridad e integridad y operaciones de administración de transacciones.
– Regla 6: regla de actualización, todas las vistas que son teóricamente actualizables deben ser actualizables por el sistema.
– Regla 7: alto nivel de inserción, actualización, y cancelación, el sistema debe soportar suministrar datos en el mismo tiempo que se inserte, actualiza o esté borrando. Esto significa que los datos se pueden recuperar de una base de datos relacional en los sistemas construidos de datos de filas múltiples y/o de tablas múltiples.
– Regla 8: independencia física de los datos, los programas de aplicación y actividades del terminal permanecen inalterados a nivel lógico cuandoquiera que se realicen cambios en las representaciones de almacenamiento o métodos de acceso.
– Regla 9: independencia lógica de los datos, los cambios al nivel lógico (tablas, columnas, filas, etc.) no deben requerir un cambio a una solicitud basada en la estructura. La independencia de datos lógica es más difícil de lograr que la independencia física de datos.
– Regla 10: independencia de la integridad, las limitaciones de la integridad se deben especificar por separado de los programas de la aplicación y se almacenan en la base de datos. Debe ser posible cambiar esas limitaciones sin afectar innecesariamente las aplicaciones existentes.
– Regla 11: independencia de la distribución, la distribución de las porciones de la base de datos a las varias localizaciones debe ser invisible a los usuarios de la base de datos. Los usos existentes deben continuar funcionando con éxito:
- Cuando una versión distribuida del SGBD se introdujo por primera vez
- cuando se distribuyen los datos existentes se redistribuyen en todo el sistema.
– Regla 12: la regla de la no subversión, si el sistema proporciona una interfaz de bajo nivel de registro, a parte de una interfaz relacional, que esa interfaz de bajo nivel no se pueda utilizar para subvertir el sistema, por ejemplo: sin pasar por seguridad relacional o limitación de integridad. Esto es debido a que existen sistemas anteriormente no relacionales que añadieron una interfaz relacional, pero con la interfaz nativa existe la posibilidad de trabajar no relacionalmente.
MOTORES DE BASES DE DATOS
¿Cuáles son los diferentes motores de bases de datos?¿Cuáles los más amigables? ¿Los hay gratuitos?
PRINCIPALES MOTORES DE BASES DE DATOS 

– Access: Es un programa sistema gestión de Base de datos relacional creado y modificado por Microsoft para uso personal de pequeñas organizaciones. Es la base de datos más amigable y versátil del mercado.
– Apache Cassandra: Es probablemente uno de los proyectos NoSQL más conocidos del mercado. Se trata de una base de datos distribuida de segunda generación con alta escalabilidad que está siendo usada por gigantes como Facebook (que es quien la ha desarrollado), Digg, Twitter, Cisco y más empresas. El objetivo es ofrecer un entorno consistente, tolerante a fallos y de alta disponibilidad a la hora de almacenar datos.
– Berkeley DB: Sistema de base de datos embedido, open source. Provee un kit de herramientas de alta performace con soporte para aplicaciones de escritorio y servidores. Soporta C, C++, Java, Tcl, Perl y Python APIs. Corre bajo Windows 95/98/NT/2000, VxWorks, Linux y Unix. Freeware para distribuciones no comerciales.
– HSQLDB: Sistema de base de datos rápido pequeño y relacional escrito completamente en java.
– Hypersonic SQL: Sistema de base de datos relacional súper pequeño creado íntegramente en java, soporta standard SQL y tiene interfaz JDBC.
Todo en menos de 100Kb.
– SQLLite: SQLite es una pequeña librería de C que implementa self-contained. Cero-configuration. Motor de base de datos SQL.
– MS SQLServer Express Edition: Versión Express, liviana, de la versión comercial de SQL SERVER DATABASE
– Oracle (diferentes S.O): Es un sistema de gestión de base de datos relacional (o RDBMS por el acrónimo en inglés de Relational Data Base Management System), desarrollado por Oracle Corporation. Se considera a Oracle como uno de los sistemas de bases de datos más completos, destacando:
• Soporte de transacciones
• Estabilidad
• Escalabilidad
• Soporte multiplataforma
– Informix (Mundo UNIX): Es una familia de productos RDBMS de IBM, adquirida en 2001 a una compañía (también llamada Informix o Informix Software) cuyos orígenes se remontan a 1980. El DBMS Informix fue concebido y diseñado por Roger Sippl a finales de los años 1970. La compañía Informix fue fundada en 1980, salió a bolsa en 1986 y durante parte de los años 1990 fue el segundo sistema de bases de datos más popular después de Oracle. Sin embargo, su éxito no duró mucho y para el año 2000 una serie de tropiezos en su gestión había debilitado seriamente a la compañía desde el punto de vista financiero.
– DB2 (AS/400 de IBM): DB2 es una marca comercial, propiedad de IBM, bajo la cual se comercializa el sistema de gestión de base de datos. DB2 versión 9 es un motor de base de datos relacional que integra XML de manera nativa, lo que IBM ha llamado pureXML, que permite almacenar documentos completos dentro del tipo de datos xml para realizar operaciones y búsquedas de manera jerárquica dentro de éste, e integrarlo con búsquedas relacionales.
FREEWARE, OPEN SOURCE O GRATUITOS
– Apache Derby: Base de datos relacional open source implementada completamente en java.
– B-Tree Filer: Sistema de búsqueda rápida de archivos, creada por Borland Delphi. Independiente de otras herramientas Borland. Gratuita open Source.
– DiamondBase: Motor de base de datos en C++ disponible para uso no comercial.
– Firebird Database: Motor de Base de datos relacional para Linux, Windows, y gran variedad de plataformas Open-source, freeware, basada en Interbase.
– FlashFiler: Freeware, open-source. Motor de base de datos SQL cliente/servidor.
– GNU SQL Server: Motor Base de datos gratis, relacional portable y multiusuario creada en C. It soporta SQL89.
– H2 Database Engine: Motor Base de datos Open source en Java soporta standard SQL y JDBC API.
– IBM’s Cloudscape: Freeware, open-source, Base de datos small-footprint. Creada completamente en JAVA.
– MySQL: Freeware, motor de base de datos gratuito, soporte multiusuario. Multithread. SQL. Versiones disponibles para Win95/Win98/NT, Linux, Solaris, FreeBSD,AIX, SunOS, etc. JDBC drivers. Freeware bajo licencia GPL.
– Ocelot: Base de datos gratuita soporta completamente ANSI / ISO SQL Standard (1992) y una lista de características de SQL3 (también conocido como SQL-99). Corre en varias versiones de windows puede ser llamada por medio de ODBC. Solo para uso personal, no distribuible.
– One$DB: Edición freeware y open source de Daffodil DB. Base de datos comercial en Java.
– Perst: Perst es un motor de bases de datos open source orientado a objetos con soporte para Java y .NET.
– PostGreSQL: Freeware. “The Vision of PostgreSQL, Inc. is to support the market dominance of PostgreSQL as the definitive freewareSQL database solutions for individuals and organizations worldwide.” Avanzada objetos-relacional DBMS, corre en varios sistemas operativos y contiene drivers para ODBC y JDBC.
– Sanchez GT.M: Industrial strength, transaction processing application platform consisting of a database engine optimized for high TP throughput and a compiler for the M (aka MUMPS) programming language. GT.M is open-souce freeware on x86/Linux.
– Sybase ASE Express: Edición Freeware de Sybase para Linux.
– Real Isam: Librería de base de datos (DLL) que se usa en el método ISAM (Indexed Sequential Access Method) para manejar indices y datos de longitud variable. Aplicable en C++, Delphi, Visual Basic, etc. Freeware en Windows.
Sistema de gestión de bases de datos
Un sistema gestor de base de datos (SGBD) es un conjunto de programas que permiten el almacenamiento, modificación y extracción de la información en una base de datos .Los usuarios pueden acceder a la información usando herramientas específicas de consulta y de generación de informes, o bien mediante aplicaciones al efecto.
Estos sistemas también proporcionan métodos para mantener la integridad de los datos, para administrar el acceso de usuarios a los datos y para recuperar la información si el sistema se corrompe. Permiten presentar la información de la base de datos en variados formatos. La mayoría incluyen un generador de informes. También pueden incluir un módulo gráfico que permita presentar la información con gráficos y tablas.
Generalmente se accede a los datos mediante lenguajes de consulta, lenguajes de alto nivel que simplifican la tarea de construir las aplicaciones. También simplifican las consultas y la presentación de la información. Un SGBD permite controlar el acceso a los datos, asegurar su integridad, gestionar el acceso concurrente a ellos, recuperar los datos tras un fallo del sistema y hacer copias de seguridad. Las bases de datos y los sistemas para su gestión son esenciales para cualquier área de negocio, y deben ser gestionados con esmero.
Las mejores bases de datos
Por Juan Carlos Acero Linares.
Las bases de datos son muy importantes en la actualidad. Vamos a contarte más de ellas y dónde puedes conseguir las mejores bases de datos en la actualidad. ¿Nos acompañas?
Debemos saber que una base de datos o banco de datos, es un conjunto de datos que pertenecen todos ellos a un mismo contexto y que se almacenan de forma sistemática para usarlos posteriormente. Una biblioteca se puede considerar una base de datos que se compone en su mayor parte por documentos y textos impresos en papel y se indexan para su consulta. En la actualidad, gracias al desarrollo tecnológico de campos como la informática o la electrónica, la mayor parte de las bases de datos están en formato digital, siendo este un componente electrónico, desarrollándose y ofreciéndose un rango bastante amplio de soluciones al problema existente en cuanto al almacenamiento de datos.
Hay programas que se llaman sistemas gestores de bases de datos, en abreviatura (SGBD) que hacen posible el almacenamiento y acceso a los datos de manera rápida y estructurada. Las propiedades, su utilización y administración se estudian en el ámbito de la informática. Las aplicaciones que se utilizan más son para la gestión de empresas e instituciones públicas, que se usan ampliamente en los entornos científicos con el objetivo de almacenar la información de carácter experimental con la mayor efectividad.

Mejores bases de datos
Lograr tener una buena base de datos es algo que toda empresa quiere. Desde que ha entrado con fuerza el big data, las empresas se han replanteado bastantes de sus procesos y operativas. Actualmente sale más económica conservar la información que prescindir de ella. Los datos dejan claro todo esto y de manera sencilla, en un solo click, podemos tener acceso a una visión global sobre la cartera de clientes. Incluso podemos decir más, se puede tener de cada uno de ellos en detalle al completo. La pregunta que muchos se hacen es la siguiente ¿Cómo le sacamos todo el beneficio? ¿Que debemos hacer para que no se nos escapen las oportunidades de negocio? Captación de bbdd.
Bases de datos de clientes
A pesar de que pueda parecer lo contrario, no es tan fácil conseguirlas como pudiera parecer. Algunos estudios recientes, han dejado claro que el 25% de las bases de datos de clientes existentes en las empresas no son del todo exactas e incluso la fiabilidad de la información del 60% de las organizaciones es reducida. Si queremos solucionar estos inconvenientes, el propio consumidor es al que tenemos que involucrar al consumidor a la hora de verificar los datos. Además, si queremos comprar bases de datos, tendrán que ser fiables, ya que de nada sirve comprar si no es de calidad y no puede ayudarnos en nuestro objetivo final de ventas.
Para ello, hay que usar la tecnología, que mediante una estructura adecuado y con buenos expertos en el tema, nos ayuden a la creación de una plataforma de clientes que logre alcanzar los objetivos deseados:
- Tomar datos en todos los procesos en los cuales se produce una interacción con el cliente. Pueden ser múltiples, desde que se consulta la web de la empresa, cuando se produce un pago o mediante la moderna tecnología móvil o las transacciones que se producen en el departamento post-venta. Lo que es evidente es que lograr una base de datos de clientes fiable no es algo fácil y tampoco se realiza de forma instantánea.
- Conseguir la información, segmentando, analizando y realizando previsiones. Con ello nos protegemos del fraude, comprendemos el ciclo de compra, las costumbres y entendemos los mecanismos que nos permiten saber qué cliente tiene más tendencia a comprar o como poder conseguir un up-sell y cross-sell efectivos.
- Proceder a transformar los datos en una visión completa que haga que se minimicen los errores y se sitúe la empresa en una posición privilegiada en la totalidad de aspectos existentes respecto al cliente.
- Debe fomentarse una relación más cercana con el cliente, esto permitirá que se produzca una conexión con la empresa en tiempo real. Esto hará posible que se puedan realizar ofertas mejores y con una mejor personalización. El resultado es positivo, puesto que una buena base de datos de clientes, es el comienzo de un aumento en la eficiencia de las ventas, una mayor lealtad del cliente y por lo tanto una mejora evidente en los ratios de conversión. Esta base de datos de clientes generada por la empresa tendrá una alta calidad y además menor coste para la empresa que si tuviera que alquilar base de datosde terceros.
Lo que te debe quedar claro es que las bases de datos de los clientes no son algo estático, es un elemento que tiene que crecer, por lo que gestionar una cuenta tiene que tener una mentalidad expansionista e intentar sacar provecho para sacar ventaja de ella. El gran potencial dinámico que tiene es el motivo por el que se puede ir revisando de forma continua, lo que hace posible que se eviten errores, datos incompletos, duplicidades o datos que inexactos). Además de todo esto podemos trabajar sobre ella, gracias a la analítica o usándola como base para acciones donde intervenga el aprendizaje automático.
Gestor de base de datos
 Lo primero que debemos saber es que un Sistema Gestor de bases de Datos de una empresa, es un conjunto de programas que se encargan de administrar y gestionar la información que tiene una base de datos. Mediante él, se puede manejar todo el acceso a la base de datos para así servir de interfaz entre ella, el usuario y las aplicaciones. Este software se compone por un lenguaje de definición de datos y un lenguaje de manipulación y consulta, siendo posible la gestión de los datos a diferentes niveles. Podemos almacenar, realizar modificaciones o acceder a la información, así como hacer consultas o realizar análisis para la generación de informes.
Lo primero que debemos saber es que un Sistema Gestor de bases de Datos de una empresa, es un conjunto de programas que se encargan de administrar y gestionar la información que tiene una base de datos. Mediante él, se puede manejar todo el acceso a la base de datos para así servir de interfaz entre ella, el usuario y las aplicaciones. Este software se compone por un lenguaje de definición de datos y un lenguaje de manipulación y consulta, siendo posible la gestión de los datos a diferentes niveles. Podemos almacenar, realizar modificaciones o acceder a la información, así como hacer consultas o realizar análisis para la generación de informes.
Un SGBD podemos entenderlo como una colección de datos que se relacionan entre sí, los cuales se estructuran y organizan en un ecosistema que lo forman un conjunto de programas que acceden a ellos y hacen más fácil su gestión. Estamos ante un sistema en el acceder a los datos se realiza con independencia de los programas que lo gestionan, lo que es una gran ventaja al tratar grandes volúmenes de información.
El gestor es el que controla cualquier tipo de operación que haga el usuario en la base de datos, usando para ello una serie de herramientas, caso de los sistema de generación de informes o de sistemas de búsqueda u otras aplicaciones.
Si hablamos de los tipos, se agrupan mediante criterios que se relacionan con el modelo de datos y también se les pueden diferenciar según sean propietarios o no, así como en base al número de usuarios o de sitios.
Principales funciones de un Gestor de datos
Una buena parte de las funciones de un gestor de bases de datos de email por ejemplo, se contienen en su propia definición, ya que hace posible la definición de los datos, su manipulación, aplicar medidas de seguridad, integridad y la recuperación o restauración de los datos después de un posible fallo. Existen muchas ventajas cuando se construye y define una base de datos para diferentes aplicaciones, facilitando los procesos y su mantenimiento. Además de esto, colabora a que se puedan realizar una serie de acciones de gran importancia como definir los datos, mantener su integridad, manipulación y el control de la seguridad o la privacidad.
Los mejores gestores de bases de datos del mercado
Hay que dejar claro en primer lugar que hay muchos tipos de lenguajes de base de datos, pero entre ellos, quizás, destaca el lenguaje SQL (Structured Query Language). Este tipo de lenguaje de consulta estructurada hace posible que se pueda acceder a la gestión de las bases de datos de tipo relacional, y hacer por lo tanto, una serie de tareas con ellas, como por ejemplo, recoger, eliminar, agregar o modificar información. A la hora de desarrollar este lenguaje, se necesitar un gestor de bases de datos. En el mercado existe una gran variedad de ellos, unos son de acceso libre otros de pago.
Gestores de bases de datos de pago

Entre los mejores gestores de base de datos y que más se usan con licencia de pago están los siguientes:
- Oracle: Este tipo de sistema de gestión, es la base de datos relacional que tiene una mayor fiabilidad y el que más se usa. Su desarrollo data de 1977 y es propiedad de Oracle Corporation. Se construyó en un marco en el cuál podemos acceder de forma directa a los objetos mediante el lenguaje de consulta SQL. Oracle es una arquitectura de tipo escalable y que se usa con frecuencia por las empresas. Cuenta con su propio componente de red, el cuál hace posible que pueda existir una comunicación mediante las redes. Su ejecución se realiza en la mayoría de las plataformas, entre las cuales podemos citar a Windows, Linux, Unix, Mac OS, etc. La pecualiaridad mayor de Oracle es la arquitectura, que divide entre lógica y física. Esto hace que exista una flexibilidad mayor entre las redes de datos y una mayor robustez en la estructura de los mismos.
- SQL Server: Uno de los sistemas que hace la competencia de forma directa a Oracle, es el SQL Server del gigante Microsoft. Tanto este último como el de Oracle, son los que cuentan con una mayor cuota de mercado en el sector de las bases de datos. SQL Server tiene muchas características con Oracle, aunque está claro que hay diferencias evidentes, ya que por ejemplo SQL Server se ejecuta en Transact – SQL, un conjunto de programas que añaden una serie de características al programa, caso del tratamiento de errores y excepciones, procesamiento de datos, extracción de datos directos de la Web, uso de varios lenguajes de programación y demás características que hacen de este SQL Server uno de los gestores más completos que existen. Una de sus características más sobresalientes es su gran carácter administrativo, tanto en las funciones y seguridad como a la hora de contar con una gran flexibilidad en sus bases de datos.
Gestores de base de datos de acceso libre
En este caso vamos a comentaros los gestores que no son de pago. Los principales gestores de acceso libre o también llamados Open Source:
- MySQL: Este es un Gestor que tiene una instalación bastante simple y que actúa del lado del cliente (servidor) y es del tipo de código abierto con licencia comercial disponible. En la actualidad es propiedad de Oracle Corporation. Se ocupa de gestionar las bases de datos relacionales, siendo multiusuario y es el que más se usa dentro del software libre. Necesita poca memoria y procesador para que funciona, lo que hace que cuenta con una mayor velocidad en sus operaciones. Se usa de forma principal en el desarrollo web.
- FireBird: Como principal característica podemos aludir a su potencia, que se acompaña con un sencillo sistema de gestión de base de datos relacional SQL. Es uno de los mejores gestores de código abierto (Open Source) y es compatible con Windows y Linux. Entre otro tipo de funciones, cuenta con un soporte completo para los procedimientos almacenados, transacciones que sean compatibles con las características ACID y métodos de acceso múltiple (Python, NET, nativo, etc…).
Podemos ver que son muchas las posibilidades a las que se tiene acceso en cuanto a gestores de base de datos, tanto comprando licencias de pago, como recurriendo al software libre. Esto claro está depende de los gustos, maneras en que se trabaje o las necesidades de cada caso, pero seguro que podemos encontrar gestores de bases de datos que van a podernos satisfacer en cuanto a nuestro trabajo profesional.
El lugar que ocupan los gestores de base de datos, es desde los comienzos de la programación de gestión hasta el día de hoy, fundamentales para que las empresas se desarrollen de forma eficiente de empresas, entes de carácter público y cualquier tipo de organismo que use datos, todo ello en un constante avance y mejora en su desarrollo. Hay que ser conscientes de la importancia que tienen estos programas informáticos, pues facilitan mucho la tarea del trabajo con bases de datos de emails por ejemplo, tanto en su creación como en su mantenimiento. Destaca en buena manera el papel del administrador de estas, ya que él puede hacer copias de seguridad, modificar, clonar o eliminar, respecto a las bases de datos que se encarga de administrar.
Bases de datos dinamicas y estaticas
- 1. Bases de Datos CLASIFICACIÓN SEGÚN LA VARIABILIDAD DE LOS DATOS ALMACENADOS
- 2. Bases de Datos Estáticas. Las bases de datos estáticas se conocen también como bases de solo lectura, puesto que se usar primordialmente para almacenar datos históricos que posteriormente se pueden utilizar para estudiar el comportamiento de un conjunto de datos a través del tiempo, realizar proyecciones y tomar decisiones. Un ejemplo de una base de datos estática es la toma de censos a través de los años.
- 3. Bases de Datos Dinámicas. En las bases de datos dinámicas la información esta almacenada y puede ser modificada con el tiempo, ya sea actualización, remoción, operación, adicción o simplemente consulta de esta. Un ejemplo de esta es la base de datos de un hotel en la cual se puede ver el historial de un cliente, puede adicionar información o borrarla según sean las necesidades o políticas del hotel.
- 4. Conclusiones Podemos concluir que la diferencia principal entre las bases de datos dinámicas y estáticas es que en la primera podemos consultar y modificar la información, mientras que en la segunda solo se puede consultar. De igual forma es de resaltar que escoger una base de datos u otra depende de las necesidades de la empresa, puesto que no vale la pena gastar recursos implementando una base de datos dinámica cuando solamente se necesita añadir y consultar datos.
Tipos de bases de datos
Existen varios tipos de bases de datos; cada tipo de base de datos tiene su propio modelo de datos (la manera de cómo están estructurados). Entre ellas se incluyen; Modelo plano, modelo jerárquico, modelo relacional y modelo de red.
El modelo de base de datos plana
En un modelo de base de datos plano, hay dos dimensiones (estructura plana) de conjunto de datos. Hay una columna de información y dentro de esta columna, se supone que cada dato tendrá que ver con la columna.
Por ejemplo, un modelo de base de datos plana que sólo incluye códigos postales. Dentro de la base de datos, sólo habrá una columna y cada nueva fila dentro de una columna será un nuevo código postal.
| Código Postal |
|---|
| 9063635 |
| 9345452 |
| 6345469 |
| 6654760 |
| 7754742 |
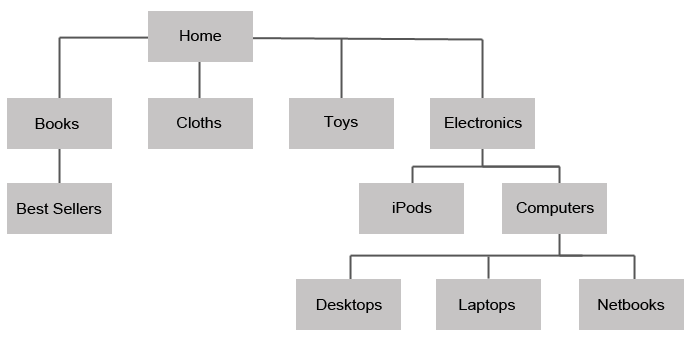
El modelo de base de datos jerárquica
El modelo jerárquico de bases de datos se asemeja a la estructura de un árbol, tal como Microsoft Windows organiza las carpetas y archivos. En un modelo jerárquico de bases de datos, cada enlace es anidado con el fin de conservar los datos organizados en un orden particular en un mismo nivel de lista. Por ejemplo, una base de datos jerárquico de ventas, puede incluir las ventas de cada día como un archivo separado. Anidadas dentro de este archivo están todas las ventas (el mismo tipo de datos) para el día.
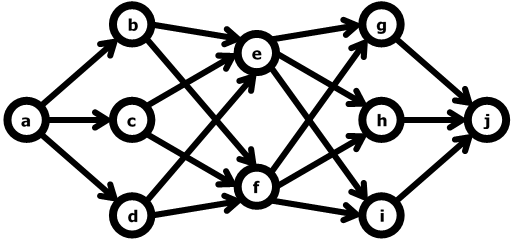
Modelo de Red
En un modelo de red, la característica definitoria es que se almacena un registro con un enlace a otros registros - en efecto,una red.
Estas redes (o, a veces, a que se refiere como punteros) puede ser una variedad de diferentes tipos de información como números de nodo de un disco o incluso la dirección.
El Modelo Relacional
El modelo relacional es el más popular tipo de base de datos y una herramienta extremadamente potente, no sólo para almacenar información, también para acceder a ella.
Las bases de datos relacionales son organizadas en forma de tablas. La belleza de estos cuadros es que la información se puede acceder o añadir sin reorganizar las tablas.
Una tabla puede tener muchos registros y cada registro puede tener muchos campos.
Hay cuadros que a veces se llaman una relación. Por ejemplo, una empresa puede tener una base de datos denominada los pedidos de los clientes, y dentro de esta base de datos habrán diferentes tablas o relaciones de todos los pedidos de los clientes. Las tablas pueden incluir la información del cliente (nombre, dirección, contacto, información, número de cliente, etc) y otras tablas (relaciones), como las órdenes que el cliente compró anteriormente (esto puede incluir un número de artículo, la descripción del artículo, cantidad de pago, la forma de pago, etc).
Cabe señalar que cada registro (grupo de campos) en una base de datos relacional tiene su propia clave principal. Una clave principal es el único campo que hace que sea fácil identificar a un registro.
Las bases de datos relacionales utilizan un programa llamado interfaz estándar SQL o Query Language.
Las bases de datos relacionales utilizan un programa llamado interfaz estándar SQL o Query Language.
SQL se utiliza actualmente en prácticamente todas las bases de datos relacionales. Las bases de datos relacionales son extremadamente fáciles de personalizar para adaptarse a casi cualquier tipo de almacenamiento de datos. Usted puede crear fácilmente las relaciones de los artículos que usted vende, los empleados que trabajan para su empresa, etc
La elección de una base de datos no es permanente, existen varios servicios de migración de base de datos que le pueden ayudar en caso que decida cambiarse a otro modelo.
Acceso a la Información de la base de datos
Si bien el almacenamiento de datos es una gran característica de las bases de datos, para muchos usuarios de estas bases de datos la característica más importante es la rápida y sencilla, recuperación de la información.
En una base de datos relacional, es muy fácil consultar información sobre un empleado, pero las bases de datos relacionales también añaden la potencia de consultas complejas.
Las consultas complejas son solicitudes para mostrar tipos específicos de información, o bien mostrarlos en su estado natural o crear un informe de la utilización de los datos.
Por ejemplo, si había una base de datos de empleados que incluye cuadros como el salario y la descripción del trabajo, puede ejecutar una consulta de empleos que pagan más de una cierta cantidad. No importa qué tipo de información se almacene en su base de datos, las consultas pueden ser creadas usando SQL para ayudar a responder a preguntas importantes.
Almacenar una base de datos
Las Bases de datos pueden ser muy pequeñas (menos de 1 MB) o muy grandes y complicadas (como en muchos terabytes de datos del gobierno), sin embargo todas las bases de datos normalmente se almacenan y ubican en el disco duro u otro tipo de dispositivos de almacenamiento y se accede a través del ordenador.
Grandes bases de datos pueden requerir servidores en distintos lugares y, sin embargo muchas pequeñas bases de datos pueden encajar fácilmente como archivos ubicados en el disco duro del equipo.
Asegurar una base de datos
Obviamente, muchas bases de datos confidenciales almacenan información importante que no debe ser fácilmente accesible por cualquiera. Muchas bases de datos requieren contraseñas y otras características de seguridad para poder acceder a la información.
Aunque algunas bases de datos se pueden acceder a través de Internet a través de una red, otras bases de datos son sistemas cerrados y sólo se puede acceder en el sitio.
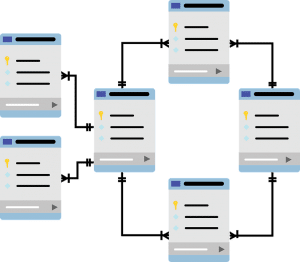
Tipos de relaciones en bases de datos
Access es un gestor de bases de datos relaciones, por lo que se hace imprescindible saber qué tipos de relaciones pueden darse entre dos tablas:
1 a 1
Aparece cuando un registro de la tabla A sólo puede relacionarse con 1 registro de la tabla B. Este modelo aparece en relaciones de tipo exclusivo, como por ejemplo Países-Banderas, ya que cada país tiene una única bandera oficial, y cada bandera sólo puede pertenecer a un país; otro ejemplo sería Matrículas de coches y Número de bastidor.
1 a varios
En este caso, un registro de la tabla A puede relacionarse con varios de la tabla B. Es el tipo más habitual y utilizado, y existen numerosos casos; por ejemplo, domicilios con personas que viven en el mismo, nombre de empresa con sus trabajadores, proveedores con productos que sirven…
varios a varios
Se da si varios registros de A pueden relacionarse con varios de B y viceversa. Es quizás la menos habitual de manera formal, aunque en futuras entradas veremos cómo podemos plantear una situación de este tipo para manejarla de forma efectiva.
El ejemplo clásico, es tener dos tablas, una de actores y otra de películas, ya que lo habitual es que cada actor haya trabajado en varias películas, y que éstas estén formadas por varios actores.
¿Cómo establecer relaciones entre tablas?
Para que Access reconozca las relaciones como tales tenemos que indicárselo; para lo cual, tras crear la estructura de la tabla y ANTES DE INTRODUCIR LOS DATOS haremos clic sobre el botón Relaciones situado en la cinta Herramientas de bases datos y después añadimos las tablas que vayamos a relacionar.
En la ventana que aparece, podemos mover dichas tablas y situarlas en la posición que nos interese. Por ejemplo, en el gráfico puedes ver que hemos incluido una tabla con todos los Alumnos de un colegio. Así como otra con todos los Exámenes que se realizan a lo largo del año.
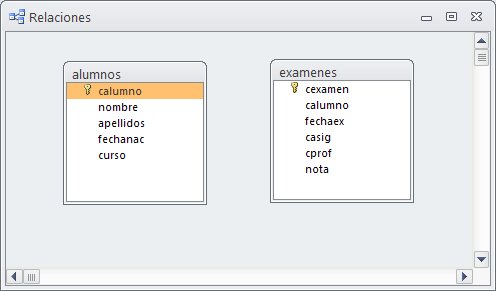
Tablas de una base de datos sin relacionar
Para hacer efectiva la relación, arrastramos el campo calumno de una tabla a otra. Los campos pueden tener nombres diferentes pero el tipo de datos debe coincidir.
Si te fijas en la parte inferior del cuadro de diálogo que aparece, Access ya reconoce el tipo de relación como de 1 a varios.

Cuadro Modificar relaciones de Access
La opción Integridad referencial, al activarse, no permitirá añadir en la tabla Examenningún alumno que no se haya creado con anterioridad. Este hecho representa una medida de seguridad interesante.
Actualizar en cascada implica que al hacer algún cambio en la tabla de origen, dicha modificación se refleje en todas aquellas tablas con las que se relacione. Por lo tanto, también resulta práctica.
Eliminar en cascada, en cambio, puede ser muy peligrosa. Si se habilitara y borrásemos un alumno, también se eliminarían los exámenes que haya efectuado.
Tras marcar las opciones que te interesen, pulsa Crear. Así verás cómo Access reflejará con una línea la relación establecida. Además, debes tener en cuenta que la aplicación identifica los extremos de tipo
varios con el símbolo de infinito.


No hay comentarios.:
Publicar un comentario